

The concepts of Data Hub, Data Warehouse, and Data Lake are central to modern data management and analytics strategies. While they are often used interchangeably, they each serve distinct purposes, architectures, and use cases.
Below is a comparison that highlights the key differences.
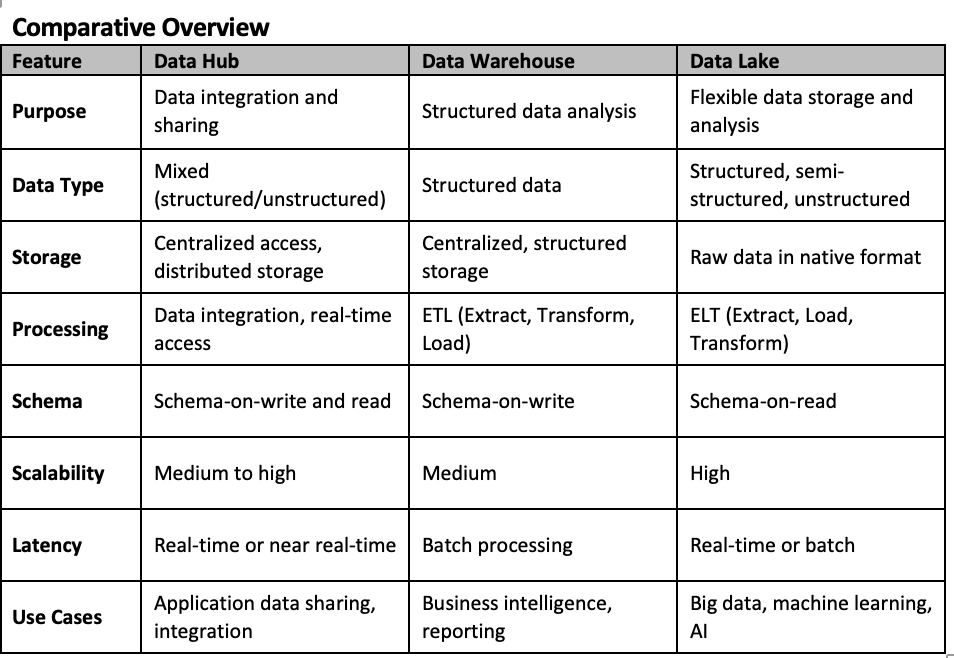
Data Hub
A Data Hub is a centralized system where data from various sources is integrated, harmonized, and shared. It acts as a mediator, allowing different systems and applications to exchange and access data without moving it from its original location.
Key Features:
Integration Focused: Acts as a conduit for sharing data across different systems, making it ideal for real-time data synchronization and collaboration.
Federated Architecture: Data can remain in its source systems, and the hub provides a unifying access point for various data consumers.
Data Harmonization: Ensures consistency by resolving differences in data formats and definitions.
Use Cases:
- Real-time data sharing between business applications.
- Centralized access to distributed data sources.
- Integration of on-premises and cloud data.
Data Warehouse
A Data Warehouse is a structured and curated repository designed for storing large volumes of data that has been cleaned, transformed, and organized for analytical purposes. It is typically optimized for querying and reporting.
Key Features:
Structured Data: Focuses on structured data in predefined schemas.
ETL Process: Data is extracted, transformed, and loaded (ETL) before entering the warehouse, ensuring it’s clean and consistent.
Historical Data: Stores historical data to enable time-series analysis and trend reporting.
Optimized for Analytics: Designed to support complex queries, reporting, and business intelligence tools.
Use Cases:
- Business intelligence (BI) and analytics reporting.
- Historical data analysis.
- Executive dashboards and key performance indicator (KPI) tracking.
Data Lake
A Data Lake is a more flexible and scalable storage system that stores both structured and unstructured data in its raw form. It allows data to be stored without a predefined schema, offering more agility compared to a data warehouse.
Key Features:
Unstructured Data: Can store data of all types — structured, semi-structured, and unstructured (e.g., logs, media files, IoT data).
Schema-on-Read: Unlike data warehouses, schema is applied to data when it is read, allowing for greater flexibility in how the data is analyzed.
Scalability: Highly scalable, allowing for the storage of large volumes of data at a relatively low cost.
Use Cases:
- Big data analytics, including machine learning and AI.
- Handling large datasets from IoT, logs, and social media.
- Staging area for data before processing and transformation.
When to Use Each:
- Data Hub: If the organization needs to integrate data from multiple systems, allow real-time access, and share data among various applications without migrating it, a data hub is ideal.
- Data Warehouse: Best for businesses that rely on structured data for generating reports, conducting time-series analysis, or using BI tools for historical data analysis.
- Data Lake: Ideal for organizations dealing with large volumes of raw, unstructured data. It’s particularly useful for big data analysis, machine learning models, and exploratory data analysis.
Conclusion:
While Data Hubs, Data Warehouses, and Data Lakes all help organizations manage and analyze data, they serve different purposes. Choosing the right system depends on the business requirements, the types of data managed, and the insights needed to derive. Many organizations use a combination of these systems to support the diverse data needs.





